

This week: the last of my commentaries on Makin and Orban de Xivry’s Common Statistical Mistakes! (Previous posts: #1-2, #3 , #4, #5, #6, #7, #8.) I’m lumping together comments on “Mistake #9” (Over-interpreting non-significant results) and “Mistake #10” (Correlation and causation), as well as concluding remarks, writing one long post instead of two or three smaller ones for a variety of reasons: next week’s journal club meeting is the last of the term, Mistake #10 doesn’t require much commentary, and I’m growing tired of painting seashores.
#9: Over-interpreting non-significant results
The mistake is believing that the failure of a hypothesis test (i.e. p > 0.05) indicates the absence of an effect. This is a bizarre thing to believe, yet it is sadly common. To illustrate, here’s some real data on children’s heart rates, specifically the difference in heart rate from the resting value when the kids were anticipating, but hadn’t yet started, exercising. (See Note [1] for the source.)
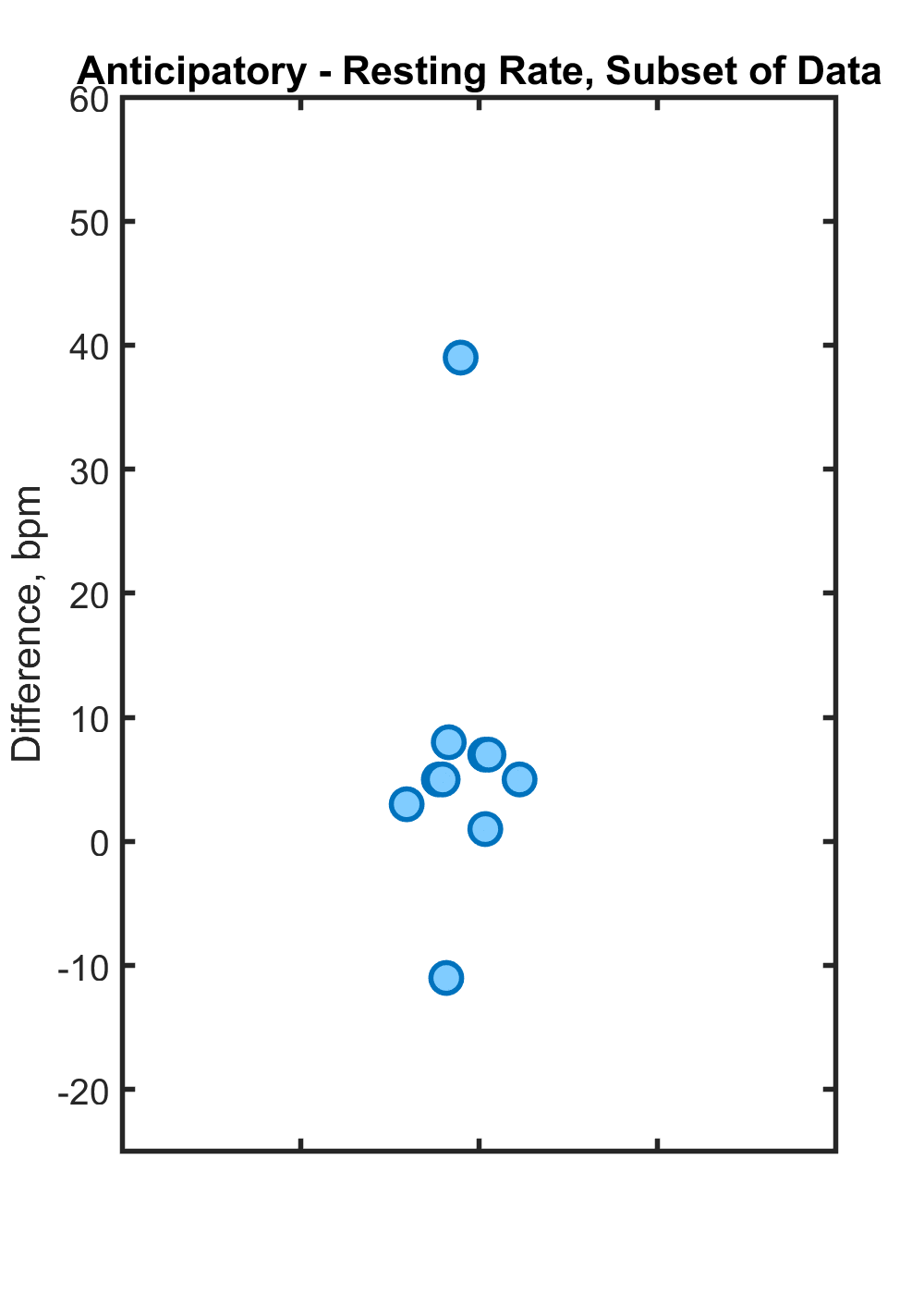
Comparing the data to zero with a t-test, we find p = 0.116. Would we conclude that there is no effect of anticipation on heart rate? The above data, however, are just a random subset of all the kids’ measurements. Here’s the complete data:

Now, p = 0.0015, i.e. it’s “significant.” Do we believe that an anticipatory effect on heart rate has magically appeared? Of course not; it was there all along. Once again, we must keep at the forefront of our thoughts that a p-value tell us nothing about effect sizes, or about the absence of effects. In fact, the mean of the subset’s values is 6.9 beats per minute, close to that of the full set’s 7.2. (The uncertainty of the mean is, of course, lower in the latter case.) If our goal were, as it should be, to estimate the effect size, rather than make unsound statements about whether effects “exist” or not, we would not trip ourselves into illogical and contradictory conclusions.
As a second illustration, let’s simulate some data in which the true effect sizes are 4, 2, and 1 for the blue, red, and yellow points, respectively (left to right in the plots). In other words, the blue set demonstrates the largest effect. The data are drawn from Gaussian distributions with standard deviations 4 ,1.5, and 0.4, respectively.

In the instance shown above, with N = 7 data points each, the p-values (for comparison to zero) are 0.17, 0.06, and 0.0007, respectively — only the yellow set gets the “*” of p<0.05. Suppose each set measures some phenotype following the knockout of some gene; would we conclude that only the yellow gene indicates an important gene for the process we’re studying? Of course not… but I’ve seen this *often* in papers. In addition to mis-understanding what a p-value means, this mistake presumes we’re at a special point in time, where exactly this amount of data is the right amount, because what would happen if we were to take more data? Think about this, while I put up a random draw with the same parameters but N = 30:

Here, p = 3.1 x 10-8, 1.0 x 10-8, and 1.4 x 10-11, respectively. All are “significant,” which shouldn’t surprise us because the p-value is always a decreasing function of N. If we take more data, p will always drop below 0.05. (Pedants may point out that this is only true if the true effect size is nonzero, but in real life, the effect size is always nonzero. Even the motion of stars a billion light years away pushes blocks on earth; surely, whatever treatment you apply has some indirect, n-th order effect on your system that’s at least as large.)
Returning to our smaller N case, it would be fine to say that the most precisely measurable effect is the yellow one, and therefore focus further attention on that, but it’s wrong to say that it’s the only effect, or the dominant effect, or the most significant effect (in the conventional use of the term).
Makin and Orban de Xivry write as a solution to this mistake that “an important first step is to report effect sizes together with p-values in order to provide information about the magnitude of the effect.” And, of course, “researchers should not over-interpret non-significant results and only describe them as non-significant.” It’s worth noting that the opposite of this mistake is also a mistake: over-interpreting statistically significant results. “Statistical significance” isn’t the same as “significance.”
#10 Correlation and causation
I think we all know that correlation doesn’t equal causation. (See also #4, Spurious Correlations.) Sometimes people seem to ignore this. This isn’t so much a statistical mistake as a failure of scientific reasoning.
The question of how one can infer causation is a difficult one. Thankfully, in experimental fields, one can at least try to perform controlled experiments, altering only the variable of interest and examining its effects. Some fields aren’t so fortunate, relying solely on observation, though sometimes “natural experiments” in which some stimulus is added or removed are possible. (For a thought-provoking recent example on car seats and birth rates, see here.) There’s a lot out there on inferring causation in more challenging contexts, intersecting philophical questions about what causality means. This looks fascinating, but I’ve never had time to look into it. Perhaps someday… (On the list, “What if” by Hernán & Robins, and stuff by Judea Pearl.)
Concluding remarks
I wrote in the first post that statistical mistakes, at least of the sort that plague a lot of contemporary research, are almost never about math. As we’ve seen, discussion of these errors hasn’t required equations or derivations. Rather, the issues involve more fundamental relationships between signals, noise, and how we draw conclusions from them.
As Makin and Orban de Xivry note, their list is very closely tied to the process of null-hypothesis significance testing, and “a key assumption that underlies this list is that significance testing (as indicated by the p-value) is meaningful for scientific inferences.” Many would argue that significance testing is not meaningful. Some would counter that by arguing that if used properly, p-values can be informative. Others (including me) would counter that by noting first that they convey no information that isn’t better conveyed by effect sizes and confidence intervals, and second that they are so amenable to mis-use that they invite unreliable and incorrect science.
More broadly, I wonder whether the underlying problem is a desire for certainty that is unwarranted by the messiness of real data. We seek strong conclusions and turn to statistical tools that seem to promise clear-cut answers, not thinking enough about what the tools really mean, and what the data are really like. Perhaps thinking about the ways these tools can be mis-applied can foster a broader understanding of how to tackle subtle, complex problems. (See also Discussion Topic #3.)
Discussion topic 1. I claim that one of the reasons Mistake #9 is so prevalent is because of the unfortunate term “significant” to denote data with p<0.05. Do you agree? What would be a better term?
Discussion topic 2. Suppose null-hypothesis significance testing didn’t exist. Which of the 10 common mistakes would still exist, perhaps in some modified form?
Discussion topic 3. My conclusions section is pretty minimal. What’s missing in it? Perhaps comment on the publication process, how we teach statistics, etc. (Do we foster in students a clear understanding that noise is real? I suggest activities that involve measuring things.)
Exercise 9.1 Download the heart rate data noted in [1] below. Repeatedly take random subsets of the data of size N, and calculate the mean change in heart rate from anticipating exercise, and the mean p-value, as a function of N. Plot this, with error bars indicating the standard deviation.
Exercise 9.2 As in 9.1, plot p-values vs. N, but this time for simulated data as in the blue/red/yellow plots, with the mean and standard deviation values given in the post.
Today’s illustration…
This seashore painting is based on a photo I took last week at Heceta Head — the photo is below. Though I’m done painting seashores for a while, it’s been enjoyable, and I’ve learned that I can use white ink.
— Raghuveer Parthasarathy, November 29, 2020
Notes
[1] From Louise Robson, University of Sheffield, very nicely described and made available at https://www.sheffield.ac.uk/polopoly_fs/1.33424!/file/Heart-teachers-notes.doc

