

Next in our series of commentaries on Makin and Orban de Xivry’s Common Statistical Mistakes, #6: Circular Analysis. (Previous posts: #1-2, #3 , #4, #5.)
I was thinking of skipping this one entirely. It’s less dramatic than #5 or the upcoming #7, I’m not sure I fully understand the authors’ intent, and my seashore painting is a step down from last week’s. But, having spent more time than I should mulling it over, I think there’s an important general point of which this mistake is a manifestation. And besides, I should be consistent in my commenting.
The mistake of “Circular Analysis” lies in using overlapping criteria for selecting data to analyze and for the analysis itself. To illustrate this cryptic statement, consider the following datapoints, let’s say representing immune cell concentration in the blood of 40 individuals:
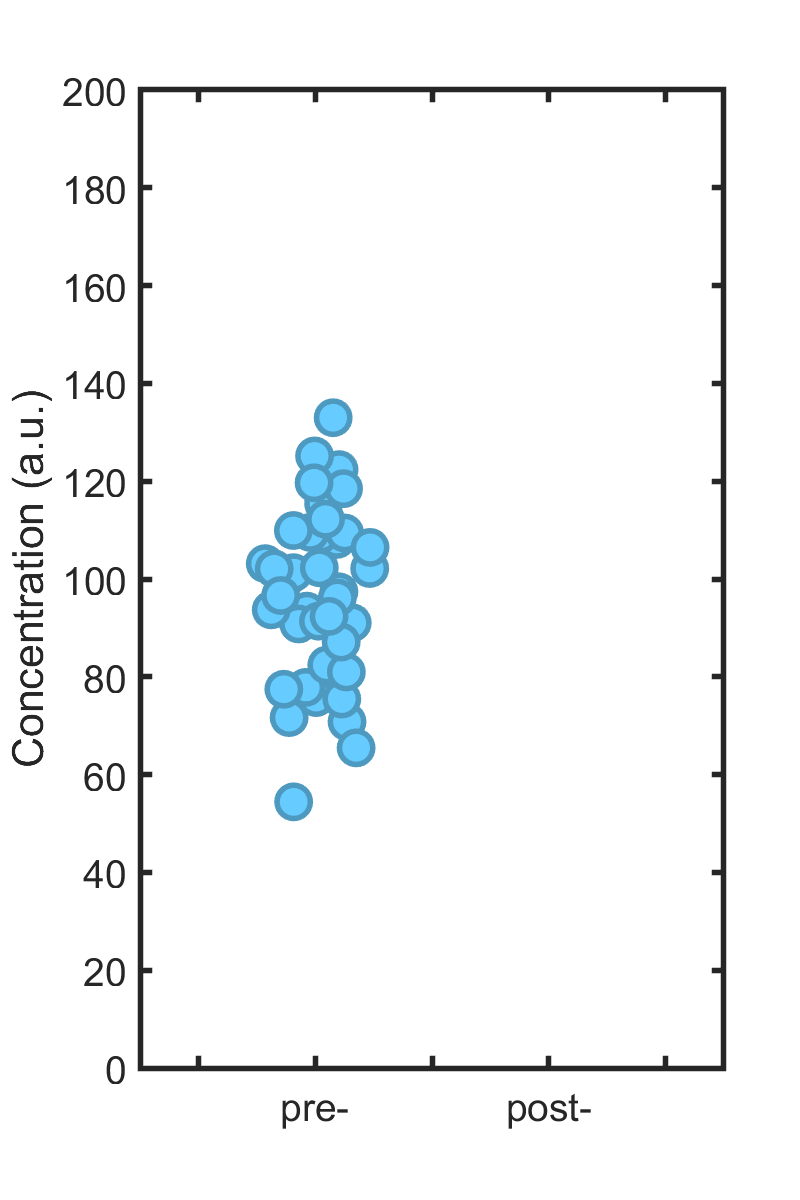
Each individual is treated with some drug, and then the immune cell concentration is again measured; we wish to know how much it has changed. (Please, dear reader, don’t ask if the concentration “is different.”) The new, post-treatment values are shown in the right hand plot. If they look similar to the old ones, that’s because the effect size is zero; I simulated 40 points with exactly the same mean (100) as the other set.
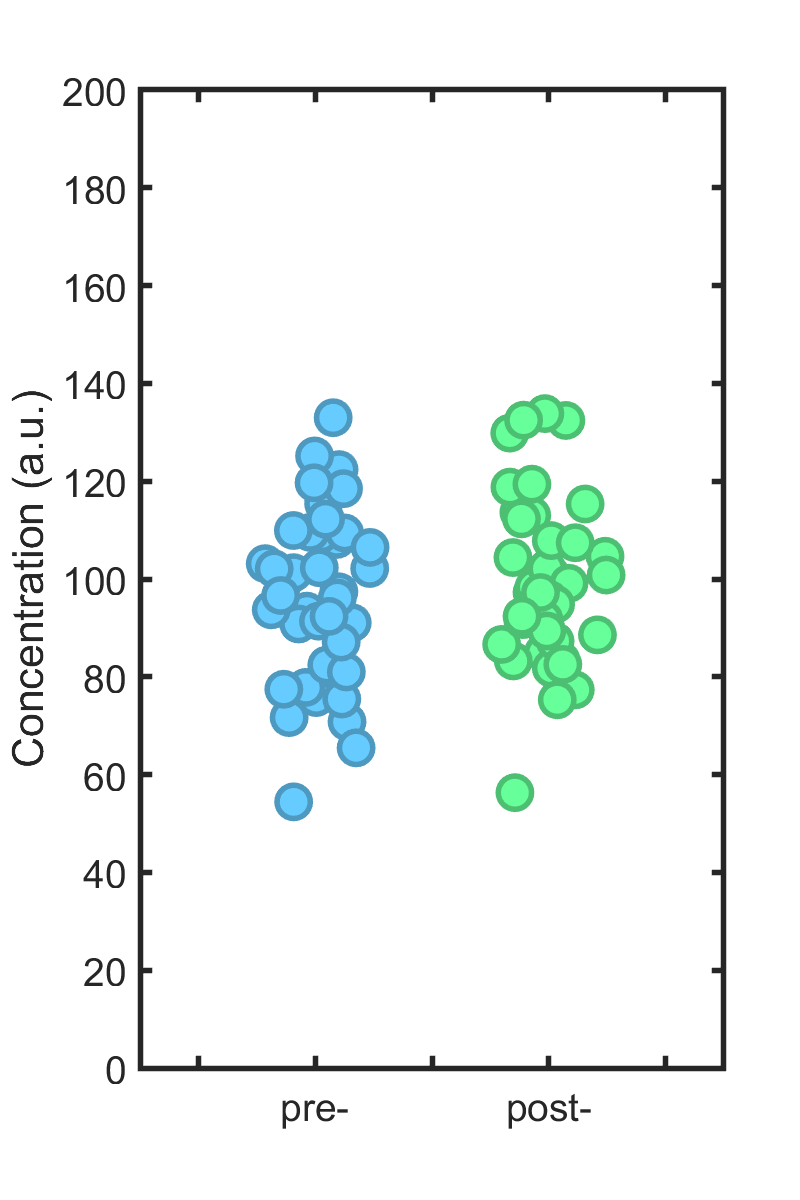
Perhaps, one imagines, there are individuals with normally high immune cell levels, or we care about values above some threshold. We take the top 25% of the pre-treatment set (orange borders, below), assess what happens to these individuals post-treatment (orange lines)…
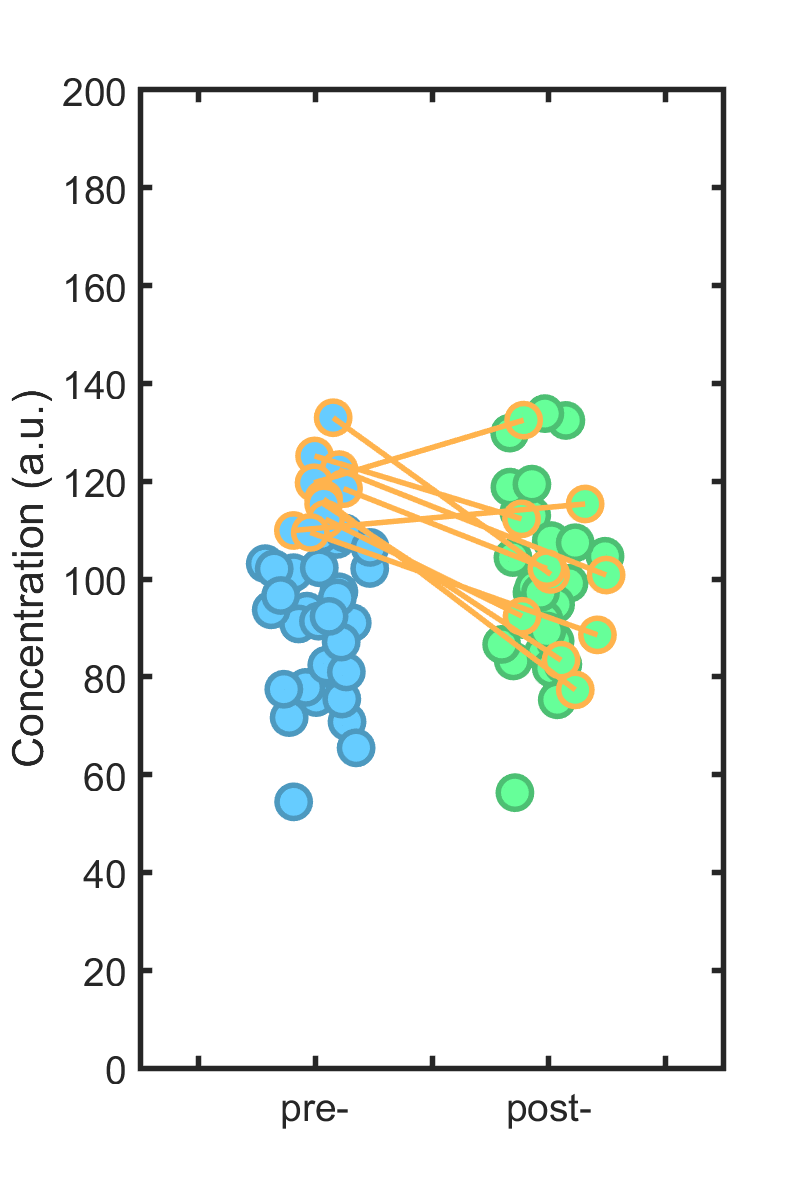
… and conclude (wrongly) that there’s a large effect! In the instance shown, the difference between the subset’s pre- and post-values is about 20, with p = 0.006 (i.e. “significant”).
If you’re thinking that there’s nothing particularly “circular” about this mistake, I agree. The term apparently precedes Makin and Orban de Xivry; they cite a 2009 neuroscience paper that uses this phrasing. That paper, cited over 2000 times to date, argues that this major flaw is common in neuroscience, especially in imaging-based analysis (e.g. fMRI).
More importantly, you may be thinking: “Isn’t this just regression to the mean?” I agree with that, too. Makin and Orban de Xivry comment that this is similar, and also note a resemblance to overfitting. Overfitting is applying a model that’s more complex than the data warrants. The orange curve below, for example, is terrible, even though it fits the data points better than the red line. The orange curve follows the wiggles of noise as if they were real, and so will be less robust to new data.

That, in essence, is the deeper message of this “statistical mistake” and those like it: The flawed analyses acts as if noise doesn’t exist, as if each bump in the data were a pure reflection of the signal we’re trying to measure, rather than being influenced by all the randomness present in reality.
The solution to all these problems isn’t some better statistical algorithm, but a better understanding of what science and data are. Even in the best controlled context, noise exists. There’s an undergraduate physics lab here at Oregon in which students measure the position of a particular brick on a wall. It should shock no one that there is scatter in the measurements, despite bricks being immobile. In anything more complex, whether its neuroimaging, the microbiome, or whatever your field is, innumerable subtle forces give even more variation. One’s measurements incorporate this noise, and one should never forget this.
Off topic: I’ll throw in a pointer to my book announcement page, which I should update at some point with news and a detailed chapter list. One task: thinking of a better title! Feel free to weigh in, or sign up for announcements.
Discussion topic. Comment on similarities and differences between “circular analysis,” regression to the mean, and overfitting. Do you agree that the underlying cause of each of these is the same?
Exercise 6.1 In the simulated example above, the true effect size is zero; both sets of numbers are drawn from a Gaussian distribution with mean 100 and standard deviation 20. Suppose we really do want to quantify the treatment response of the “high level” individuals, say those with levels above 110, without being deluded by noise. Design an experiment that allows this. Simulate its outcomes, and comment on the sample sizes needed to uncover true effects of various sizes. (Yes, this is vague, and unlike the other exercises I haven’t worked through it myself.)
Today’s illustration…
A rocky shore, with a circular pool.
— Raghuveer Parthasarathy, November 5, 2020
