

This week’s commentary on Makin and Orban de Xivry’s Common Statistical Mistakes covers #7: Flexibility of Analysis: p-Hacking. (Previous posts: #1-2, #3 , #4, #5, #6.)
I feel like this has been discussed ad nauseum,* yet the problem still exists. The issue is that flexibility in how one analyzes data, even seemingly innocuous flexibility, can falsely lead to a “p < 0.05” claim of statistical significance. Even if applied properly, p-values are a mediocre measure, an easily mis-interpreted statistic that reveals nothing about the effect sizes and uncertainties one should care about. But it’s worse than that: p-values are easy to apply improperly. (* See e.g. Kerr 1998, Simmons 2011, Head 2015, Gelman 2013 and many, many more.)
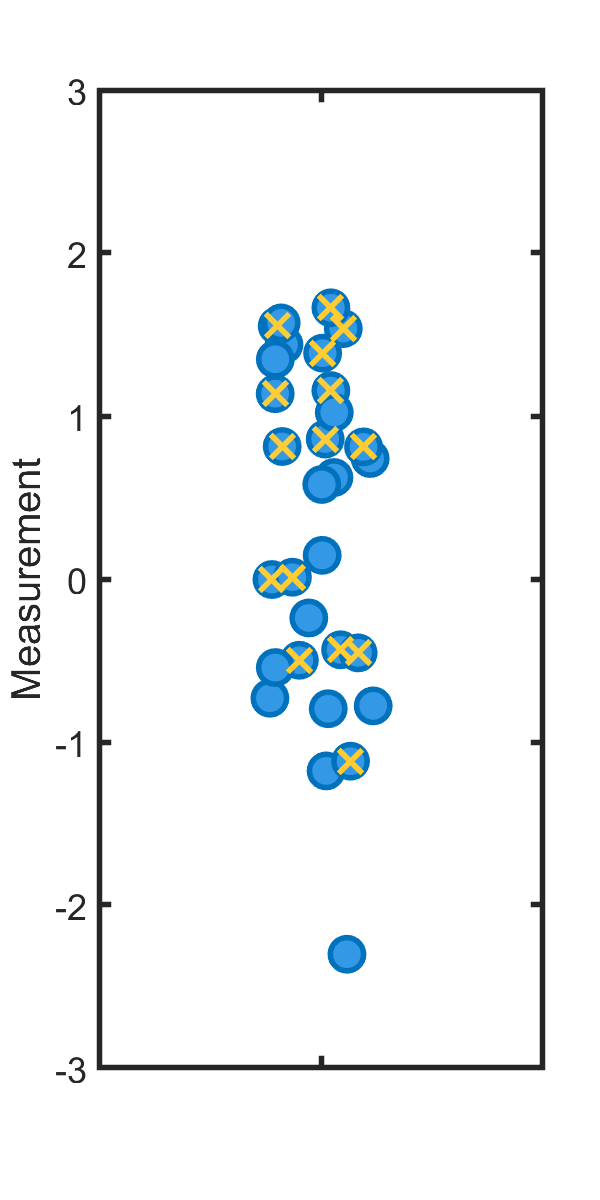
Suppose, for concreteness, that one measures a bunch of values as shown (blue points), perhaps the change in people’s heart rate after taking some drug, and one wants to assess whether the signal is “significantly” different from zero. Suppose further that p > 0.05 for the dataset — a “non-significant result.” I did, in fact, draw the simulated points from a distribution with zero mean, so the true effect size is zero. How might one massage the points to yield significance?
An obviously awful approach would be to simply remove the low points, perhaps arguing that they’re outliers or otherwise bad, shifting the mean above zero and p to something less than 0.05. But one doesn’t have to be so deliberate to get a similar result.
Suppose instead that one decides, in retrospect, that one should have considered men and women separately. Slicing the data this way, one finds that for women (x’s in the plot), the subset of data compared to zero gives p<0.05, and one publishes the result that there’s a significant effect of the drug on women.
This is deeply wrong. Why? The probability that a bunch of random points with zero mean gives p<0.05 is 5%, by definition. The probability that either those points or a random subset of those points gives p<0.05 is something more than 5%. (It couldn’t be less!) Again using our simulated example we could ask: what’s the probability that if we generate 30 random points, and then pick half the datapoints at random, either the full set or the subset gives p < 0.05 when compared to zero in a simple t-test? The answer is about 8%. (It’s very easy to simulate.) Seeing “p < 0.05” in a paper, in other words, only means p<0.05 if the researchers didn’t have the flexibility to decide on their analysis after the fact. (Or, if they described and corrected for the more flexible analysis.)
An old example: stopping times
There are many ways to p-hack. One that I wrote about a long time ago (2013!) is to keep running your experiment! Suppose p > 0.05; why not keep collecting data, and then stop if the new, larger set of data gives p < 0.05? After all, it’s definitely true that more data, and more information, are good! It’s worth pausing and thinking about this, if you haven’t before.
The answer is that the p-value is itself a random number, and fluctuates with the fluctuations of the data. Again by chance, we might find p < 0.05, and the freedom to stop whenever we want makes it more than 5% likely that somewhere along the way we’ll find p < 0.05. It’s easy to imagine, however, a researcher not realizing this, and happily publishing a “discovery.” It’s also easy to imagine the analysis method not being transparent to other researchers — when’s the last time you read a paper that described the authors’ decisions about when to stop collecting data? The answer is never. The reader is simply presented with a p-value.
Forking Paths
Again, this problem of p-hacking is well known. There’s even an xkcd comic about it! (It’s a great comic, though one should realize that the p-hacking is there even if we don’t search through all 20 M&M colors…) It goes by many names: data dredging, data slicing, HARKing, and my favorite, the Garden of Forking Paths (from Andrew Gelman; see e.g. here, or many blog posts). There are always many paths the researcher analyzing data can take; the existence of these paths must influence our interpretation of likelihoods.
Solutions
As Makin and Orban de Xivry note, one solution to the problem of p-hacking is to pre-register one’s experimental design and analysis methods, and stick to the plan. This avoids the possibility of forking paths. It does, unfortunately, also make it harder to discover (true) unexpected things.
Another approach, that Andrew Gelman often notes, is to account for the multiple paths in one’s analysis. In other words, actually calculate the probability that the process you used — a flexible stopping time, for example, shows an effect even if the true effect size is zero.
Yet another approach is to do a new experiment, with the analysis path suggested by previous exploration now fixed. (This is similar to pre-registration.)
And, of course, one can do science that doesn’t rely on p-values, and push (somehow) for a world in which publication isn’t tied to silly significance tests.
Discussion topic 1. Here we have two examples of flexibility in data analysis. Think of others.
Discussion topic 2. If you read p = 0.04 in a paper, do you believe that there’s a only 4% chance that the observed effect size could arise by chance? Why or why not?
Exercise 7.1 In the first example above, I stated that there’s an 8% chance that either a random subset of half the datapoints or the full dataset shows p < 0.05, for a t-test of Gaussian points of mean zero and standard deviation 1. Reproduce this. Then: what if I allow myself to take two random subsets? Three? Four? Show how this probability increases with the number of slices I allow myself to make.
Exercise 7.2 Collecting more data gives more information, and allows better estimates of whatever it is one is trying to measure. As noted above, collecting more data can make it easier to reach false conclusions of statistical significance. Explain how both of these statements can be true.
Today’s illustration…
Another rocky shore. This one took much longer than I expected, without a great payoff. I should have made use of the flexibility of stopping times and left it unfinished. On the other hand, spending bits of time on it offered some respite during an extremely packed week. I based the painting on this video of a rocky shore. It’s amazing that so much technology is being harnessed to bring a 10 hour video of a shoreline to us, for free.
— Raghuveer Parthasarathy, November 13, 2020
