

This week’s installment of comments on Makin and Orban de Xivry’s Common Statistical Mistakes deals with #8: Failure to Correct for Multiple Comparisons. (Previous posts: #1-2, #3 , #4, #5, #6, #7.)
Makin and Orban de Xivry’s description is rather complex, but the error is a simple one. To illustrate: suppose we have a control group (gray in the plot below) and several different test groups, for example populations exposed to different drugs, or different genes whose expression levels we’re measuring, or pixels of different intensities in an MRI image. We see one of these (orange) is “significantly different” if it’s compared to the control set, with p < 0.05, and we conclude that we’ve found something meaningful.

The problem is essentially the same as the previous topic of p-hacking. (I would have grouped these into one item if I were writing the eLife article.) This is convenient, since I spent too much time on last week’s post and so can spend less time on this one! I’ll phrase the underlying issue this way: A p-value isn’t simply a property of the data alone, but also carries with it aspects of the process.
The process, in the example above, is looking at multiple measurements. We can’t just ask, “is the probability less than 0.05 that this dataset would show a particular value?” Rather, we have to ask, “is the probability less than 0.05 that any of several datasets would show a particular value?” The odds of rolling a die and getting a “6” are 1/6; the odds of rolling 6 dice and finding at least one “6” are much higher (67%).
Here’s another way to think about this: In the plot above, the mean and standard deviation of the orange points are 1.46 and 0.82, respectively; the control’s are 0.64 and 0.75. If I had only measured the control and orange datasets…
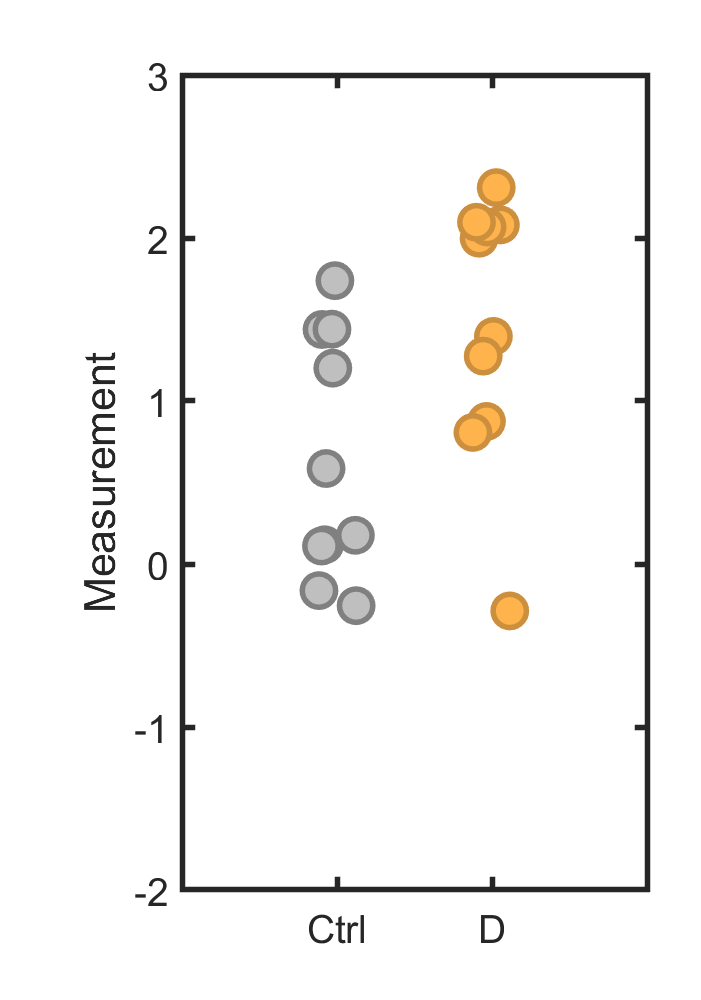
… the mean and standard deviation of the orange points are 1.46 and 0.82, respectively; the control’s are 0.64 and 0.75. Obviously, nothing has changed. However, in the latter case, p = 0.03; there’s a 3% chance that two draws from an identical random number generator (as I used) would give values as different as we see. In the former case, the numbers are exactly the same, but the true p-value, not a pairwise comparison but the actual probability of finding a dataset that’s “significantly different” than the control, is much more than 3%. (See Exercise 2.) For the p-value to mean anything, we have to account for the multiple comparisons we could make.
There are statistical treatments for correcting p-values for multiple comparisons, but less abstractly one could simulate the properties of multiple random processes as occur in one’s experiment (e.g. the 5 test groups above) and calculate what the likelihood of various observations is. What does p < 0.05 actually look like? Even better, one can use the multiple comparisons as a starting point for new experiments that take away this freedom, experiments that look specifically at the group that may be demonstrating an effect.
Discussion topic 1. I claim that this is the same issue as p-hacking. Do you agree or disagree? Explain.
Discussion topic 2. Why is it difficult to detect whether researchers have committed this error when reading papers?
Exercise 8.1 You roll twenty-one twenty-one-sided dice. The probability that one of them shows “12” is therefore 1/21, which is less than 0.05. What’s the probability that at least one of the dice shows “12”? (You should be able to quickly write an equation for the exact solution.).
Exercise 8.2 Recreate the graphs above, where each set of points is 10 values drawn from a Gaussian distribution of mean = std. dev. = 1 . Simulating this many times, what’s the probability that at least one dataset has a mean differs from the control set’s mean by 0.82 or more (the difference between orange and gray above)..
Today’s illustration…
Water, shore. You know the routine.
— Raghuveer Parthasarathy, November 20, 2020
