
 Synopsis: (1) We’re posting preprints, for the reasons that you’re probably already familiar with. (2) I can entertain myself by making graphs and models, this time about article metrics.
Synopsis: (1) We’re posting preprints, for the reasons that you’re probably already familiar with. (2) I can entertain myself by making graphs and models, this time about article metrics.
Preprints
A few months ago we posted our first, and a few weeks ago our second, papers on bioRxiv, the fairly new preprint server for life sciences. The well known arXiv has been a heavily-used repository for preprints in various fields of physics, math, astrononomy, and other disciplines for over two decades, and the idea of launching something similar for bio-related fields has been percolating for quite a while. (“Various fields of physics” is an important qualifier — use of arXiv is ubiquitous in, for example, theoretical high energy physics, but is rare in all the areas of biophysics and materials / condensed matter physics that I’ve worked in.)
Why did we post papers on bioRxiv? The usual reasons:
- It allows our work to be rapidly disseminated. Publication in journals is notoriously slow and capricious. On average, many months lie between the submission of a paper for publication and its appearance “in print” in a journal, during which time the paper is, at least in the authors’ opinion, ready to be seen by others but is hidden away.
- As a preprint the paper can be easily shared, searched for, cited, and read by anyone who is interested in it. I’ve been able, for example, talk about our lab’s recent work at conferences and point people to preprints they can read for more information. Did anyone actually read the preprints we posted? Yes — I’ll graph the numbers, below. Being able to cite the work is also useful, for example for grant and fellowship applications. It’s much more informative to give a link to an actual manuscript than to vaguely write “manuscript submitted.”
- Relatedly, preprints are free and accessible to everyone, not hidden by journal subscription fees.
- There’s no strong reason not to post preprints. A worry has always been that journals won’t accepts papers that have previously appeared somewhere, i.e. that posting a preprint will harm a paper’s ability to be published. This isn’t a fundamental problem, however, but rather just an attribute of publishers’ policies. Clearly, this hasn’t been an issue for the fields covered by arXiv. Thankfully, it seems increasingly not to be an issue for fields covered by bioRxiv, with a large and growing number of journals explicitly stating that preprints are fine. (Here’s a useful list.)
Are there even stronger motivations for preprints? Perhaps. In an interesting essay, Ron Vale argues that papers these days require a lot more data than papers in days past, contributing to the increase in the time it takes graduate students to get degrees, among other problems. He suggests that a virtue of preprints is that they could allow the rapid dissemination of smaller units of information. (There’s much more in the essay about preprints.) I agree with the motivation behind this — too many papers are too massive — but not the conclusion: the number of papers out there is already too much, and more small papers won’t help this. The underlying problem, I would argue, is that there are too many scientists, and a system that stresses competition between them — but that’s an issue for a separate post!
Another often-stated motivation is that pre-prints, if widely used, plus commentary from readers is a better system than the present one of (mostly) peer-reviewed journals, due to speed and due to the often low quality and randomness of the peer-review process. A pre-print-dominated landscape does seem to work well in, for example, theoretical high energy physics. I’m increasingly sympathetic to this view but, it should be noted, the fields in which preprints are most dominant are fields that are small and tightly knit. (I get the sense from my colleagues that all particle theorists know each other, and can keep track of all the new papers that appear!) In most areas, the deluge of papers is enormous, and conventional peer-review and journal publishing does act as a filter, albeit not a very good one. (More on that some other time.) Plus, peer-reviews can actually be useful; one can get good suggestions from reviewers, and I’d like to think that the many hours per paper I spend reviewing manuscripts contributes something to the quality of the scientific literature. Related to this: it is clear that no one writes comments about papers on journal or preprint sites. Empirically, the idea that the scientific community will provide post-publication commentary that will replace peer review seems simply false. Why is this? Why do I routinely spend hours reviewing paper, but not writing on-line comments? I’m not sure — this is an interesting psychological question!
Fun with article metrics
BioRxiv, unlike arXiv, posts data on how many abstract views and PDF download each paper gets. The first paper we posted, on March 9, was this one:
M.J. Taormina, R. Parthasarathy, “Active Microrheology of Intestinal Mucus in the Larval Zebrafish.” bioRxiv, (2016). [Link]
It relates to our lab’s general interests in the gut microbiota, and the very open question of what the physical environment experienced by gut microbes is like. Not surprisingly, this is a difficult thing to investigate, since the gut, especially at length-scales experienced by bacteria, is hard to examine. Mike Taormina, a postdoc in the lab, managed to get magnetic microparticles into the intestines of larval zebrafish and oscillate them with magnetic fields at a wide range of frequencies. The response reveals the viscosity of the intestinal fluid at microscopic scales. This is the first time such a viscosity, inside the gut of a live organism, has been measured.
Has anyone read the paper? Since I was curious, I kept track of the bioRxiv site. Here’s the data:

So, the answer is ‘yes’ — there have been well over 100 downloads of the article, by people who now don’t have to wait until the paper is “really” published. (This will take a while; we submitted it to a journal, and have to do difficult new experiments to deal with reviewer comments.) So, I’d certainly state that the posting has been worthwhile.
The symbols show the abstract views and PDF downloads. It’s a nice, smooth curve, so it occurred to me that it might be interesting to think about a simple model that can describe its dynamics. Let’s imagine that:
- there’s an immediate spike in readership when the paper is posted
- there’s an initially large rate of viewing that declines over time, but never reaches zero
Exercise 1: Come up with a simple equation that has these properties, that might describe the growth of the number of views y with time t .
… pause …
What immediately came to mind is:
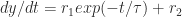
in other words, exponential decay of some initial rate 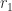

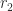
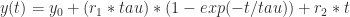
where 
The model (solid curves, above) fit the data well — perhaps remarkably well. (It might not be so remarkable — there’s not a huge amount of data, the data are constrained to be monotonically increasing, and a combination of a linear and an exponential term is pretty general — so it’s not too shocking that a four-parameter model fits well.) For the abstract views and PDF downloads, the decay times are
How does our more recent paper do? This one is on figuring out competition between bacterial species in the gut, using imaging to reveal that inter-bacterial competition can be dominated by the species’ different responses to the physical environment of the host intestine. (This was just accepted yesterday by PLOS Biology — the bioRxiv version is the earlier draft, before revisions based on some very good reviewer comments. We’ll post later a modified bioRxiv PDF that says ‘look at the published PLOS Biology version.’) Here are the article metrics, together with the fit curves from the first paper:

There’s nothing profound to conclude from this, but it’s fun to see. If I continue tracking this, will it follow a similar curve to the first paper’s? Will the ‘actual’ journal publication change the trajectory of the bioRxiv metrics? Will this post?
Exercise 2: Come up with at least two other models of article-metric dynamics, and comment on (i) whether they describe realistic behaviors, and (ii) how you could assess whether one model is “better” than another, and what that means, and (iii) whether there’s anything to be gained by creating and using such models.
The exercises, of course, aren’t actually intended for anyone’s use. I’m constantly struck by absurd statements about models in talks and papers, though, and so I wish more people were asked questions like the ones above. For 2.iii: I’m just doing this for fun! Certain large federal funding agencies, however, use metrics like this (including “citations per dollar” — really) as determinants of funding policies, for which I hope they have a well-thought-out underlying model of article dynamics.
Today’s illustration: A quickly-done onion (watercolor).
