
What makes a good exam question? Not surprisingly, I try to write exams that most students who are keeping up with the course should do well on — almost by definition, the exam should be evaluating what I’m teaching. But I also want the exam to reveal and assess different levels of understanding; it would be useless to have an exam that everyone aced, or that everyone failed. Also not surprisingly, I’m not perfect at coming up with questions that achieve these aims. For years, however, I’ve been using the data from the exam scores themselves to tell me about the exam. Here’s an illustration:
I recently gave a midterm exam in my Physics of Energy and the Environment course. It consisted of 26 multiple choice questions and 8 short answer questions. For the multiple choice questions, I can calculate (i) the fraction of students who got a question correct, and (ii) the correlation between student scores on that question and scores on the exam as a whole. The first number tells us how easy or hard the question is, and the second tells us how well the question discriminates among different levels of understanding. (It also tells us whether the question is assessing the same things that the exam as a whole is aiming for, roughly speaking.) These are both standard things to look at, and I’ll note for completeness there’s lots of literature I tend not to read and can’t adequately cite about the mechanics of testing.
Here’s the graph of correlation coefficient vs. fraction correct for each of the multiple choice questions from my exam:

We notice first of all a nice spread: there are questions in the lower right that lots of people get right. These don’t really help distinguish between students, but they probably make everyone feel better! The upper left shows questions that are more difficult, and that correlate strongly with overall performance. In the lower left are my mistakes (questions 6 and 15): questions that are difficult and that don’t correlate with overall performance. These might be unclear or irrelevant questions. Of course I didn’t intend them to be like this, and now after the fact I can discard them from my overall scoring. (Which, in fact, I do.)
I can also include the short answer questions, now plotting mean score rather than fraction correct (since the scoring isn’t binary for these). We see similar things — in general the correlation coefficients are higher, as we’d expect, since these short answer questions give more insights into how students are thinking.
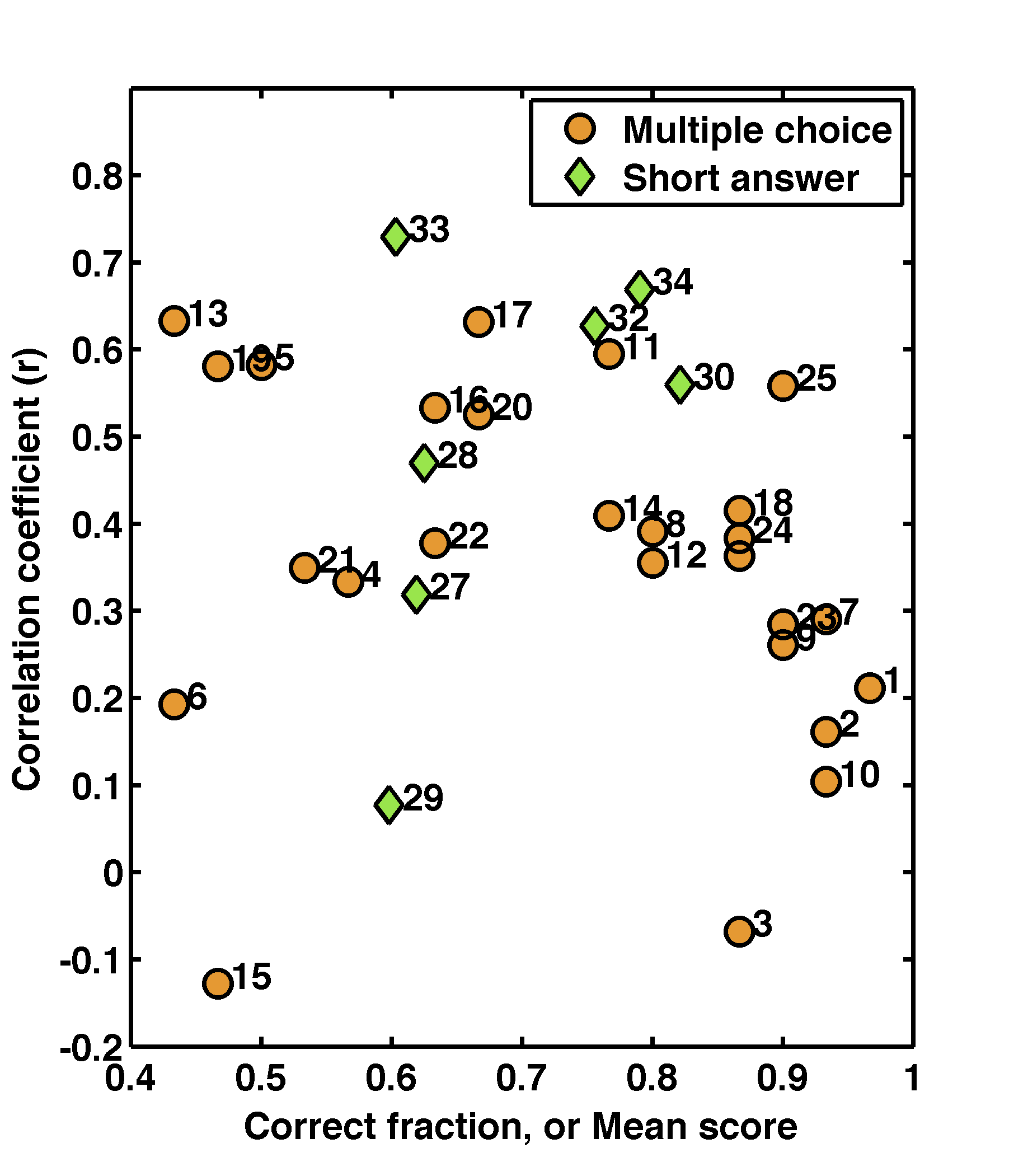
It’s fascinating, I think, to plot and ponder these data, and it has an important goal of assessing whether my exam is really doing what I want. I’m rather happy to note that only a few of my questions fall into the lower-left-corner of mediocrity. I was spurred to post this because we’re doing a somewhat similar exercise with my department’s Ph.D. qualifier exam. One might think, given the enormous effect of such an exam on students’ lives, and the fact that a building full of quantitative scientists create it, that (i) we routinely analyze the exam’s properties, and (ii) it passes any metrics of quality one could think of. Sadly, neither is the case. Only recently, thanks to a diligent colleague, do we have a similar analysis of response accuracy and question discrimination. Frighteningly, we have given exams in which a remarkable fraction of questions are poor discriminators, correlating weakly or even negatively with overall performance! I am cautiously optimistic that we will do something about this. Of course, it is very difficult to write good questions. However: rather than telling ourselves we can do it flawlessly, we should let the results inform the process.

Really interesting idea to try to evaluate your qualifying exam!
The part-whole correlation is a useful index only if you accept an underlying assumption, which is that people who do well on one question should be doing well on the others. That works out in undergrad classes, where there is lots of individual-difference variation in things that should affect performance across the board — ability, motivation, previous experience with the subject, etc.
That may also be true of Ph.D. students taking a qualifying exam, but there are a couple of reasons I would wonder about it. One is statistical: the students are already heavily selected on being good at physics, and that can distort correlations among the things that go into that. (I wrote a blog post about a related issue not knowing that it was already an established principle in statistics called Berkson’s Paradox, which itself turns out to be a special case of something Judea Pearl calls “conditioning on a collider. The commenters clued me in: https://hardsci.wordpress.com/2014/08/04/the-selection-distortion-effect-how-selection-changes-correlations-in-surprising-ways/)
The second reason I’d wonder is that Ph.D. students are in a process of specializing, and so some of them may simply be better at some areas of the field than others. I don’t know about physics, but in psychology we don’t even do comprehensive exams. It’s a broad field, and by the time they’re ready to advance to candidacy, students need to have invested so much time specializing. So they do papers or tailored exams in their sub-sub-field. Given a hard enough comprehensive exam, I would expect even our best third-years’ knowledge to look uneven.
Like I said, I don’t know enough about physics to know whether that applies. Either way, it would be neat if you were also able to collect some kind of criterion information down the road — job market success, quality or impact of papers published in grad school, or whatever you think is appropriate.
Hi Sanjay,
These are very good points. I think it is likely, though, that the assumption “that people who do well on one question should be doing well on the others” is a fairly good one even for our Ph.D. exam. Students take it in their first year (and sometimes in their second) — before they specialize in any particular area. Also, it is essentially an undergraduate-level exam, and covers “standard” topics that everyone has (at least on paper) seen before, so one would expect some good amount of correlation based on the existence of the sort-of-standard “canon” of physics education. There are four main subject areas covered by the exam (classical mechanics, quantum mechanics, electromagnetism, and statistical mechanics), and it would be useful to see if correlations within subjects is, as one would hope, better than between subjects. We’ve never done this. It might be easier to do in the future — not that it should be hard now — since some of us are proposing an explicit partitioning of the exam into four sub-exams.
About your first point, that we’re already selecting for students who are good at physics, so correlations become weak or meaningless: this is tougher to think about. (I remember your ‘burgers and fries’ post, by the way — it was neat!) Mean scores on our exam tend to be low (~60%), and I would expect that this Berkson’s Paradox is more pronounced if ceilings are important — i.e. without much dynamic range to discriminate with. I’m not sure of this, though. I’m also not sure if Berkson’s Paradox applies to the sort of intra-exam correlations I’m thinking about here. It seems more relevant to the question of correlation between the exam performance and student “quality,” since we’ve selected students based on some \*combination\* of exam-taking abilities plus other characteristics, and then we give them an exam.
I strongly agree with your last point, that it would be great if we looked at some sort of data on student “success,” by whatever metric, even subjective faculty opinions. I’ve brought this up before. We don’t do it.
Random comment: I met someone a month or two ago who seemed quite sure I was you. I restrained myself from pointing out that I’m the other Indian…
Raghu
Well that makes a lot of sense. It sounds like you do qualifying exams very differently than we do (I should have known better than to assume!). And I agree that the Berkson’s issue may not apply. It would be relevant if there were distinct physics competencies that affected selection *and* that mapped onto different exam questions. Which sounds like it isn’t the case. (That’s also probably a discipline difference – in psych, many students start specializing before they even get to grad school.)
BTW 3 out of 8 social/personality psychology faculty at UO are men of South Asian descent (which is a funny little cluster, it is not at all representative of the field). As you might imagine we get mixed up from time to time. Even more opportunities for you to get mistaken for a psychologist!
I had a student that did poorly on any question that required memorization (this student would write gibberish words in place of Drosophila gene names, for example) but had amazingly clear explanations of any kind of mechanistic question. Other students show proficiency at certain kinds of learning and do poorly in others. I think any class has too few questions to develop a good profile, but it would be cool (and time-consuming) to tag every question in every class with the kinds of thinking needed to answer it and develop individual training plans to work on weak areas.
Hi Eric,
This reminds me a bit of Bloom’s taxonomy. Wikipedia: http://en.wikipedia.org/wiki/Bloom%27s_taxonomy ; I’ve read a much better description somewhere, but I can’t remember where. I’ve exhausted my powers of recall trying to remember the name “Bloom’s taxonomy,” which took me a few minutes. I empathize with your student.
— Raghu
Hmm, I was just trying out a sequence assembler that uses a Bloom filter to reduce memory usage, but it looks like Bloom was not an exceptional polymath but instead 2 people.